
Legislative requirements are an important consideration in any big data project. This helps specify certain boundaries for the project and identify any limitations for using specific data types.
The identification, collection, use and storage of data must be carefully controlled throughout the project and within each stage of the data analysis process.
Data protection and privacy concerns
When carrying out data analytic activities, especially here in Australia, organisations must take the necessary measures to ensure that they protect the privacy rights of individuals throughout the project. Data protection involves data security through the collection, storage, access and use of data.
Following are some of the issues that need to be considered by businesses when working with big data. 7
- Data protection – regulatory requirements dictate that personal data must be processed for specified and lawful purposes and that the processing must be adequate, relevant and not excessive.
- Privacy – when dealing with confidential and sensitive information included in the big data being tested, businesses need to be transparent on how the information is handled and protected and demonstrate that confidentiality is maintained at all stages.
Personal information may need to be removed before running analytics, and considering that many systems run in real-time, careful filtering of incoming data may be required.
Issues such as the physical location of where the data is stored, the security of access to the data, the lawful use of the data and the type of personal information need careful consideration. Strict legislation needs to be adhered to throughout data collection and analysis.
Watch the following video to understand how the Australian Public Service (APS) is committed to protecting the personal information of Australians. Pay close attention to how you can identify ‘personal information’ and how this information should be handled.
After watching the video answer the following questions.
Knowledge check
Complete the following two (2) tasks. Click the arrows to navigate between the tasks.
Data protection and privacy laws and regulations
Privacy Act in Australia
The Privacy Act 1988 makes provisions to protect the privacy of individuals in Australia. Therefore, businesses that deal with the personal information of individuals in Australia must ensure that they comply with this legislation.
Watch the following video to understand what ‘privacy information’ is and how personal information requires to be protected according to the Privacy Act in Australia.
After watching the video answer the following question.
Knowledge check
The Australian Privacy Principles (APPs)
Under the Privacy Act 1988, the Australian Privacy Principles (APPs) provide guidelines for the collection, management and use of personal information. Refer to the following sources and reference guides published by the Office of the Australian Information Commissioner (OAIC) for more detailed information about the APPs.
- Australian Privacy Principles
- Australian Privacy Principles guidelines
- Australian Privacy Principles quick reference
- Guide to data analytics and the Australian Privacy Principles - This resource specifically describes how the APPs specifically apply to data analytics activities.
Knowledge check
Complete the following six (6) tasks. Click the arrows to navigate between the tasks.
General Data Protection Regulation (GDPR)
The European Union (EU) has some data protection requirements in the General Data Protection Regulation (GDPR). A business operating in the EU or collecting information about individuals in the EU will need to understand the ramifications of the GDPR. While some GDPRs align with the APPs, there are some stark differences and complexities.
According to the guidance document Australian entities and the EU General Data Protection Regulation (GDPR) published by OAIC:
Australian businesses of any size may need to comply if they have an establishment in the EU, if they offer goods and services in the EU, or if they monitor the behaviour of individuals in the EU. 9(OAIC 2018)
Privacy laws and regulations for specific industries
As well as the Privacy Act, several other laws cover privacy. They apply to areas such as financial transactions, health information and telecommunications.
The APS Big Data Strategy document published by the Office of the Australian Information Commissioner (OAIC) outlines a number of other legislative controls that apply to businesses that operate in various industries. Some examples are given below. 10
- Health Records and Information Privacy Act 2002 (HRIP Act)
- Telecommunications Act 1997 (Part 13)
- Telecommunications (Interception and Access) Act 1979
Data protection and privacy laws of states and territories
The Privacy Act is a federal law, and different states and territories have additional legislation. Further information about what may apply can is available on the OAIC website.
Here are some examples of data protection and privacy legislation as it applies to different states and territories in Australia.
- The Information Privacy Act 2009 (Qld)
- Public Sector (Data Sharing) Act 2016 (SA)
- The Privacy and Data Protection Act 2014 (Vic)
- The Personal Information Protection Act 2004 (Tas)
- Privacy and Personal Information Protection Act 1998 (NSW)
Other legislation
Other legislation that may apply to the collection and processing of data, as outlined by OAIC include: 11
- Data-matching Program (Assistance and Tax) Act 1990 - Allows data matching across different government assistance agencies.
- The National Health (Data-matching) Principles 2020 (under the National Health Act 1953) - Allows data matching from health providers for Medicare compliance purposes.
- Competition and Consumer Act 2010 - Safeguards consumer data and how this data may be used.
- Data Availability and Transparency Act 2022 - Sets out how Commonwealth bodies can share public sector data.
Government agencies have a set of guiding principles allowing some private information sharing. Watch the following video to learn why this is allowed and what type of information can be shared.
Knowledge check
To analyse big data, first you must be familiar with some of the most frequently used terms and concepts.
Big data formats

Big data formats generally fall into one of three main types. Let’s further explore these types to understand the differences.
Expand each item below to see more details.
Structured data refers to data that is identifiable and organised in a defined way. 10 Therefore, this type of data is easier to search and analyse as its elements are addressable for effective analysis. Structured data is usually stored in a database having one or more tables.
Some of the identifiable features of structured data are that: 12
- it is organised into a well-designed format (e.g. tabular)
- it is generally stored in relational databases (e.g. SQL, MySQL, Oracle) and enterprise management systems (e.g. ERP, CRM)
- it is less flexible and less scalable as it confines to its pre-defined structure
- it is easier to query and process this data to obtain meaningful results
- it allows for parallel processing of data and is often used to capture transactional data generated from multi-tasking systems such as point-of-sales terminals, retail systems etc.
Unstructured data refers to data with little identifiable structure 10 and cannot be contained in a row and column database.
Unstructured data can be textual (e.g. email body, log files, documents, social media posts) or non-textual (e.g. audio, video, images).
Some of the identifiable features of unstructured data are that: 12
- it does not have a pre-defined data format
- usually stored in datalakes*
- it does not have a specific format or structure
- it cannot be stored in traditional relational databases
- it does not contain any identifying tags or keywords
- it is harder and more complex to query and process this data to obtain meaningful results
- it requires a specialised skillset to analyse and model this type of data.
* A datalake is a centralised repository that allows general storage of all data types from any source.
Semi-structured data refers to data that does not conform to a formal structure based on standardised data models. 10 As semi-structured data appears to be unstructured at first glance, it is often hard to clearly differentiate between these two types. 13
However, some of the identifiable features of semi-structured data are that: 12
- it is not fully formatted as structured data
- it is organised up to some extent (e.g.CSV, XML, JSON, HTML), but not at the level of structured data
- it is not stored using tabular formats or in traditional relational databases
- it is more flexible and scalable than structured data, but when compared with unstructured data, it is less flexible and scalable
- It is best managed in NoSQL databases
- it contains identifiable tags or keywords that help query and process the data somewhat more easily than unstructured data. However, the process is not as easy as structured data.
Knowledge check
Complete the following two (2) tasks. Click the arrows to navigate between the tasks.
Internal vs. external big data sources
Identification of whether the sources of big data are internal or external is important.
Expand each item below to see more details.
Internal sources of big data are those generated, owned and controlled by your organisation.
Some examples of internal data sources include:
- Transactional data and point of sale (POS) information - which includes both current and historical data that relates to the organisations’ own purchases and details of their customers’ purchasing trends.
- Customer relationship management system (CRM) - this holds details of customers, which can be further analysed to understand where customers are located geographically and their company affiliations.
- Internal documents - Today, internal documents are mostly in digitised form (PDFs, Word Documents, Spreadsheets etc.), and they provide a wealth of information about business activities, policies and procedures.
- Archives - Historical data can contain a wealth of information on how the business used to operate and help further investigate patterns or to resolve issues.
- Device sensors - Any Internet of Things (IoT) device used within the organisation can generate data on network connectivity as it relates to the business. For example, a transport company can use sensor data received from their vehicles to source valuable information such as milage, fuel consumption, travel route etc.
External sources of big data are those generated outside of your organisation.
Data obtained from external sources may include:
- public data (e.g. publicly available data for machine learning, official statistics, forecasts)
- unstructured data (e.g. social media posts)
- other types of data gathered by third-party organisations (e.g. Peak body data, Government data, data collected from Google).
Your organisation may obtain permission to use these sources but does not own or control them.
Transactional vs. non-transactional data
Big data types are often defined and identified based on whether it has a time-dimension attached to it or no. That is, either as transactional or non-transactional.
Let’s further explore each big data type to understand the differences.
Expand each item below to see more details.
Transactional data sources have a time dimension and become historical once the operation is complete.
Important facts about transactional data are as follows: 15
- They consist of records that relate to any financial transactions relating to a business
- They are generated by various systems and applications such as point-of-sale servers, ATMs, payment gateways etc.
- Each record contains a transaction ID accompanied by a series of items that are part of the transaction.
- They lose their relevance over time and become historical once a transaction is completed. Therefore, processing and making sense of this type of data need to be done quickly in order to maintain a competitive edge.
- Used to understand peak transaction volumes, peak ingestion rates, and peak data arrival rates.
- For example, transactional data may contain:
- sales order data (e.g. revenue, cost, discounts, products purchased, quantity)
- financial data (e.g. purchases, sales, payments, claims)
- account transfer data (e.g. withdrawals, credits, debits)
- work-related employee data (e.g. time-in, time-out, hours worked)
Refer to the following article that explains transactional data in more detail. What is Transactional Data? | TIBCO Software
Data sources that are relevant to an organisation for a longer duration.
Example: customer details, product details.
Important facts about non-transactional data are as follows: 16
- Non-transactional data is more relevant to an organisation over a long period of time than transactional data.
- Non-transactional data may be contained within transactional data. For example, customer details (e.g. name, address, preferences, contact details) may be contained within an invoice transaction.
Knowledge check
Raw data vs. datasets
When working with big data it is important for analysis to understand the difference between ‘raw data’ and ‘datasets’.
Expand each item below to see more details.
Raw data – refers to big data that is in its natural form and is unprocessed. This includes large amounts of data acquired from various big data sources (e.g. internal, external, batch, real-time, interactive etc.) and formats (e.g. structured, unstructured, semi-structured).
This type of data is also known as ‘primary data’ or ‘dirty data’ and needs to be transformed, oganised and cleaned (i.e. pre-processed) before the usual processing steps and analysis. Raw data is incompatible with conventional data models.
Raw data does not have any meaning, but it has the potential to be processed for further analysis. For this reason, businesses invest in resources to collect and store raw data for processing at a later date.
After testing, validation and transformation from raw data to a dataset, businesses can proceed with analysis to obtain insights.
The term ‘dataset’ refers to big data that is already transformed, cleaned and organised. It is also referred to as ‘cooked data’. 18
A dataset is more manageable and had gone through preliminary data cleaning processes so that it is ready for further analysis. Analytical models can be run easily on big datasets to produce accurate findings and would improve the overall big data analysis process.
It can also be noted that datasets are derived from raw big data and are often considered as subsets or representative samples of raw big data.
Knowledge check
Complete the following five (5) tasks. Click the arrows to navigate between the tasks.
Sources of uncertainty within big data
Evaluating uncertainties within big data is not an easy task. However, identifying the sources of uncertainties is a key step that can be followed by using various measures to combat it.
Therefore, mitigating uncertainty in big data analytics must be at the forefront of any automated technique, as uncertainty can have a significant influence on the accuracy of its results. 19(Hariri et al. 2019)
Uncertainties within big data can occur due to any of the following reasons:
- Problems with the way the data was collected, leading to systematic issues such as bias
- Problems with scalability (e.g. a tool may be unable to handle an infinitely large dataset)
- Problems with converting between data types (e.g. from unstructured to structured data)
- Problems with dealing with incomplete and/or different formats of data
- Problems with inconsistencies in data cleaning, or in the ways data is named/labelled
- Problems with the way a data analysis tool or technique is applied to a dataset.
Various forms of uncertainty within big data can negatively impact the effectiveness and accuracy of the results, such as:
- noisy data
- missing data
- incorrect data
- unreliable data
- conflicting data
- ambiguous data
- incomplete data
- poor quality data
- inconsistent data
The reasons for any form of uncertainty to be present in big data can be explained using the big data characteristics we have discussed previously. Out of the 5 Vs of big data, mainly volume, variety, velocity, and veracity are the characteristics that introduce numerous sources of uncertainty within big data. 19

Let’s expand each of the following big data characteristics to learn how it is associated with the uncertainties found within big data.
Volume
The ever-increasing size and scale of big data, makes it harder to be processed using traditional database systems as the capabilities of these systems may not be able to handle infinitely large datasets. This can create uncertainties when the database systems try to scan and understand the data at scale.
Variety
When conversions are performed between different types of data (e.g. structured, unstructured, semi-structured), uncertainties can arise. For example, converting unstructured data to structured data. Traditional big data algorithms have limitations when handling data from multiple formats.
Velocity
Due to the speed of data processing, especially in real-time systems, delays in processing the data can cause uncertainties within the big dataset.
Veracity
Due to the increasingly diverse sources and data varieties, accuracy and trust are more difficult to establish. Uncertainties can exist within the big data as data from these various sources can be noisy, ambiguous or incomplete.
Knowledge check
Complete the following two (2) tasks. Click the arrows to navigate between the tasks.

Creating data models is one of the most important tasks that a data analyst is required to do.
Let’s explore the key elements that make up a data model.
Tables
Tables contain one or more columns that specify what type of data should be stored on each column. Then the actual data records are stored within the rows of a table.
To make things clear, consider the following terms and their definitions.12
- Table- a structured list of data of a specific type. (e.g.
Customer table,Order table,Suppliers table) - Column- a single field in a table. All tables are made up of one or more columns. (e.g. In a
Customer tablecolumn names could beCustomerID,CustomerName,Phone,Email) - Row- a record in a table
- Datatype- this refers to the type of allowed/restricted data in a column. (e.g. characters, numbers etc)
- Schema or model- information about database and table layout and properties.
- Key column(s)- a column (or set of columns) whose values uniquely identify every row in a table.
Consider the following Customer table as an example of how structured data can be stored in a database.
Notice that:
- the table column headings (e.g.
CustomerID,CustomerName,Phone,Email) indicate what type of information about customers is stored in the table - the table rows contain records of specific customer details
- the table contains a key column (e.g.
CustomerID) to uniquely identify each record in the table.
| CustomerID | CustomerName | Phone | |
|---|---|---|---|
| 2658 | Fiona Black | 0426 142 866 | fiona.black@mail.com |
| 1952 | Benjamin Low | 0496 100 200 | benlow@mail.com |
| 2587 | Grace Murray | 0423 654 258 | gmurray@mail.com |
| 9542 | John Kelly | 0438 962 800 | kellyjohn@mail.com |
In data models, used for data analysis, data tables are defined as either a ‘fact table’ or a ‘dimension table’. These fact and dimension tables are connected to each other through key columns.
Fact tables 20
Fact tables contain observational or event data values. Such as sales orders, quantities, product prices, transactional dates and times and so on.
A fact table typically contains several repeated values. For example, one product can appear multiple times in multiple rows for different customers on different dates.
Fact tables are larger tables that contain many columns and rows of data.
Dimension tables 20
Dimension tables contain details about the data in fact tables. Such as, customer details, employee details, supplier details, product details and so on.
Dimension tables contain unique values. For example, one row of each customer in the Customer table and one row of each product in the Products table.
Dimension tables are typically smaller as they are limited to the number of unique items in a specific category of data in that table.
Relationships between tables
Relationships or links between tables are established to enable quicker and easier data analysis. To create a relationship between two tables, the key columns of the tables are linked together.
The types of relationships that can be formed between tables are as follows: 21
This describes a relationship where a row in Table A can have only one matching row in Table B. This requires unique values in both tables. This type of relationship is not recommended to be used in data models. Best practice is to combine the tables.
A one-to-one relationship is shown in the following image. Note the number "1" next to both tables indicating one matching row.

This describes a relationship where one row in Table A, matches many rows in Table B. A many-to-one relationship is the other way around. This is the most common type of relationship between fact and dimension tables. A one-to-many relationship is shown in the following image. Note the "*" represents "many".

A many-to-one relationship is shown here.

This describes a relationship where many rows in Table A are matched to many rows in Table B. It does not require unique values in either of the tables forming the relationship. This type of relationships is not recommended to be used in data models as it introduces ambiguity. A many-to-many relationship is shown in the following image.

The following image shows an example of a data model. Notice that:
- the boxes represent tables of data
- each line item within the box represents a column
- the lines that connect the boxes represent relationships between the tables.

Data models (schemas)
When preparing the dataset for analysis, data analysts must choose to implement the most optimised data model using the appropriate strategies to meet the needs of the data analysis project.
To create a data model from a flat table (a large table that contains many columns and rows of data) into multiple tables, the following strategies are commonly used. 22
- Normalisation – A process used to organise the single flat table into multiple tables correctly (using the most optimised relationships between tables) as it meets the requirements of the analysis.
- Denormalisation – A strategy used to increase the performance of a data model structure by combining data from various dimension tables into a single table.
When implementing a data model, there are two commonly used data model options to choose from; ‘star schema’ and ‘snowflake schema.
The names of these data models arise from the representation of this shape as shown in the following diagram. The star schema has a centralised shape and the snowflake schema has extra dimensions splitting out from the centre.

Let’s further discuss the differences between these two schemas.
Star schema 23
- The star schema is the simplest schema design.
- It is optimised for large dataset queries due to having a denormalised data structure.
- It has a centralised fact table linking each dimension table. That is, one fact table is surrounded by multiple dimension tables, forming a star-like structure.
- In this model, only a single join is used to define a relationship between a fact table and a dimension table.

Snowflake schema 23
- The snowflake schema is a more complex schema design.
- The snowflake schema also has a central fact table but has multiple links from one or more dimension tables. That is, one fact table is surrounded by dimension tables and dimension tables are also surrounded by other dimension tables.
- This schema requires less memory and it is easier to add dimensions, but running queries is less efficient and maintaining the structure is more complicated.

Knowledge check
Complete the following three (3) tasks. Click the arrows to navigate between the tasks.
Data classification vs. categorisation
First, let’s clarify the difference between the following terms as they are used interchangeably in the industry.
- Data classification is done based on the sensitivity of data. For example, an organisation may classify some data as general, confidential, top-secret, etc. Classification ensures the security of sensitive data and compliance with privacy and data protection regulations. Data classification is widely used in governments, militaries, financial institutions and so on. 24
- Data categorisation, on the other hand, is based on the type of data and not based on the sensitivity of the data (i.e. who should have access to what). These categorised data can also be classified based on sensitivity to give the data an additional dimension, greater granularity, and clarity. 24
Data categorisation
It is important to categorise data to help determine the type of visual display, the data analysis technique to apply or the statistical model to select. Also, the software applications used to analyse the data would need the specified data type categorisation to improve computational performance. Specifying the data type as a variable determines how the software will handle computations for that variable.
Data categorisation could be defined as the process of collecting, sorting and storing data in a manner that will enable easy retrieval when needed as well as access for retrieval, editing and deleting only to a defined set of personnel, or positions, based on the policy of the company. 25(Oworkers 2022)
It is necessary to categorise the dataset in preparation for analysis. Common classification categories include, but are not limited to the following:
- Text
- Audio/Video
- Web
- Network
Let’s explore these basic data categories of analytics in detail.
Text

This includes data in the form of words.
Texts are sequences of words and nonword characters, often organised by sections, subsections and so on. 26(Bruce & Bruce 2017)
Some examples of text data that users generate include:
- online reviews
- email body text
- text message data (can be from social media posts, mobile phones etc.)
- information from customer surveys
- text from documents and records (e.g. text files, pdf, WORD documents)
- transcripts (e.g. from call centre conversations, videos, dramas and movies).
Audio/Video
This includes data in the form of sound (audio) and motion pictures (video). Some examples of audio/video data can be generated, captured and stored by:
- call-centres (e.g. audio recordings of communications with customers)
- CCTV security/surveillance cameras (e.g. video recordings of specific building sites, traffic monitoring, etc)
- online video feeds - live streamed or uploaded audio/video (e.g. YouTube, Netflix, live stream news etc.)
- Dashcams in vehicles
- Satellite imagery.
Sound data (Audio)
It is important to understand that unlike other types of data, sound data is not easy to represent in tabular format. Sound is a mix of wave frequencies that occur at different intensities. Therefore, audio data needs conversion to some form of a tabular dataset before performing any analysis. 27
Video motion pictures
Video data is often analysed to automatically recognise temporal and spatial events in videos. Such as: 28
- a person who moves suspiciously
- traffic signs that are not obeyed
- sudden appearance of flames and smoke.
Watch the following video to observe how video data from a storefront is analysed.
Web
Web data includes data that is readily available on the World Wide Web. It is generally structured within semi-structured formats such as HTML web pages, CSS (Cascading Style Sheets), Really Simple Syndication (RSS) feeds, XML or JavaScript Object Notation (JSON) files.
This type of data can be captured explicitly from:
- social media sites (e.g. Facebook, Twitter etc.)
- company websites
- news portals
- web Blogs
- internet searches
Gathering data from the web is known as ‘web scraping’. Watch the following video for more details on web scraping.
Network
Information technology (IT) and telecommunication systems continue to grow in size and complexity, especially with the Internet of Things (IoT) gaining popularity. Each year, billions of new IoT devices are connected. 29 Some examples of data within this category include:
- Data from sensors in IoT (e.g. home automation systems etc.)
- Location tracking data (e.g. mobile phones, laptops, smart devices, sensors etc.)
- Data from computer systems (e.g. network traffic, data usage)
- Logs from network servers (e.g. user access logs, network traffic logs)
- User network and web activity logs
Watch the following video to understand the application of network data as it is used for analytics.
Knowledge check
There are a variety of techniques used to analyse transactional and non-transactional big data. Let’s explore some of these techniques.
Data mining

Data mining is used for the purpose of discovering trends and patterns in big datasets. Data mining is done by using specialised software tools and algorithms that have the ability to look for patterns and relationships between the data in big datasets. 30
Data mining is the process of uncovering patterns and other valuable information from large data sets. 31(IBM 2021)
It is important to store big data in a centralised repository such as a data warehouse, from where organisations can then analyse various datasets according to their requirements.
Some examples of where data mining techniques are used are as follows. 23
- Database marketing
- Fraud detection
- Spam email filtering
- Discerning the sentiment or opinion of users
- Loyalty card programs offering product discounts for targeted customers.
Watch the following video to learn more about data mining.
Knowledge check
Refer to the article What is Data Mining? | IBM and complete the following two (2) tasks. Click the arrows to navigate between the tasks.
Ad hoc queries
An ad hoc query can be defined as:
A non-standard inquiry created to obtain information as the need arises. 32(PCMag 2022)
Queries are generally predefined and routinely processed whereas ad hoc queries are non-routine and unplanned. Some characteristics of ad hoc queries are that they are: 33
- created to answer immediate and specific business questions
- not known in advance.
An analyst creates ad hoc queries to obtain information from the dataset outside the regular reporting or predefined queries. Some advantages of using ad hoc queries are to: 34
- dig deeper into data beyond the usual reports and find answers to more current business questions.
- provide the flexibility for analysts to find answers to specific questions depending on the data they are analysing and specific business requirements.
- help businesses make data-driven decisions faster by quickly responding to dynamic changes as ad hoc queries are done on-demand.
This table summarises the main differences between more regular static reports and ad hoc queries.
| Static report | Ad hoc analysis |
|---|---|
| Automated and produced regularly | Produced once |
| Developed by an analyst | Run by a user |
| Reports on ongoing activity | Answers a specific question |
| More formatted, with text and tables | More visual |
| Distributed to larger audience | Shared with smaller audience |
Examples of ad hoc queries could include: 35
- Sales: To analyse the effect of a particular promotion or marketing campaign.
- Banking and finance: To match external data to customer behaviour.
- Healthcare: To gain insight into particular health issues and increase efficiency.
- Government: Better allocation of resources across different levels of government.
- Education: Analyse student engagement and success rates.
Knowledge check
Operational and real-time business intelligence
Business intelligence (BI) refers to the procedural and technical infrastructure that collects, stores, and analyses the data produced by a company’s activities. 36
Operational Business Intelligence (OBI)
Operational business intelligence (OBI or operational BI) is the process of reviewing and evaluating operational business processes, activities and data to make tactical, strategic business decisions. 37
Watch the following video that explains Business Intelligence and how it is used in an organisation . Pay close attention to what Operational Business Intelligence is and what it is used for.
Real-time Business Intelligence (RTBI)
Real-time business intelligence (RTBI or Real-Time BI) is the process of sorting and analysing business operations and data as they occur or are stored. RTBI is important in scenarios that require live business insight in a fast-paced environment. 38
With RTBI, big data from different elements of an organisation are collated and processed in real-time to provide insights for decision-making. The insights gained facilitate efficiency improvement measures and may extend to detecting anomalies and planning preventative maintenance.
Watch the following video to understand how real-time business intelligence is used in organisations.
Examples showing how businesses can benefit from deploying RTBI: 39
- Retail
- supply chain improvements to satisfy demand
- dynamic pricing to improve inventory management
- customise customer experience based on historical activity
- Logistics
- optimise delivery routes
- dynamically track and alter pick-ups and drop-offs
- increase vehicle usage efficiency
- Manufacturing
- reduce production downtime
- reduce supply chain delays
- adapt to customer demand
- improve warehouse management efficiency
- Banking
- analyse trends and gain insight to customer habits
- customise offers to attract new and retain existing customers
- Energy
- optimise operation of electricity supply grids
- analysis of grid failures to help improve performance
- improve grid efficiency to reduce emissions
- Health
- increase bed occupancy
- optimise length of stay
- improve ICU patient monitoring
- assist medical diagnosis
Knowledge check
Text analysis 40
It is important to understand the difference between text analysis, text analytics and text mining as these terms are used interchangeably in the industry.
- Text analytics refers to drawing patterns, themes and trends from text-based data to produce quantitative results.
- Text Mining uses Machine Learning (ML) and Natural Language Processing NLP to pull information about opinion, urgency emotion or topical categories to understand human language.
Both text analytics and text mining are used to identify customer sentiment towards an organisations’ product or brand based on survey responses or product reviews. Text analysis is used for qualitative insights where sentiment is detected in language, topic and context in any free-form text.
Text analysis is used across different industries, such as:
- Healthcare: to find patterns in doctor’s reports or detect disease outbreaks from social media data
- Research: to explore published literature for trends and patterns
- Product development: to identify trends by reviewing customer feedback
- Customer experience: to discover sentiment around a service or experience
The following article from Microsoft Docs, Connect to AI Insights in Power BI Desktop provides some important information about how text analytics in Power BI can be used to perform, sentiment analysis, key phrase extraction, language detection etc.
Knowledge check
The final activity for this sub-topic is a set of questions that will help you prepare for your formal assessment.
Knowledge check
There are a variety of tools used to analyse transactional and non-transactional big data. In this module, you will be using Microsoft Excel as one of the key tools to perform analysis tasks. Therefore, let’s explore the features and functions of Microsoft Excel.
Excel and big data
Microsoft Excel is a spreadsheet product that is commonly available and understood. It has evolved alongside personal computers and is a valuable tool for data analysis. Excel may not have all the required features of other specialised analytic tools, but it does offer some great features and functions to perform advanced analytics of external big data.
Read through the article Excel and big data to learn about Excel’s role in big data.
Watch the following video to learn more about Microsoft Excel and how it is still a relevant tool for analysts to use when working with big data.
Knowledge check
Excel Functions
Excel has many functions required by data analysts. You will need to become familiar with the commands and know where to obtain more information about the functions that are built into Excel.
Excel functions are typically categorised by their functionality type. Some examples are as follows:
- Date and time functions
- Statistical functions
- Logical functions
- Match and trigonometry functions
- Database functions
- Lookup and reference functions
Watch the following video to learn about some of the common functions in Excel and how they are used in data analytics.
Knowledge check
Complete the following two (2) tasks. Click the arrows to navigate between the tasks.
Excel features and built-in tools
There are a variety of features and built-in tools available in Microsoft Excel.
The following table summarises some of the common features and tools used for advanced data analytics which you will be required to use at a later stage in this module. Explore these features and tools, by further referring to the recommended Microsoft documentation.
| Excel features and tools | Purpose and usage | Microsoft’s reference document |
|---|---|---|
| Analyze data | A feature used to help understand the data through natural language queries that allows you to ask questions rather than write complex queries. | Analyze Data in Excel (microsoft.com) |
| PivotTables and PivotCharts | Used for summarising, analysing, exploring and presenting summary data. | Overview of PivotTables and PivotCharts (microsoft.com) |
| PowerQuery | Used to import, connect to external data and then transform the data as required. | About Power Query in Excel (microsoft.com) |
| PowerPivot | An Excel ad-in used to perform powerful data analysis and create complex data models. | Power Pivot: Powerful data analysis and data modeling in Excel (microsoft.com) |
| Trendline | Used to display a best-fit line on charts to identify patterns in the data. There are different trendline options available for use in Excel. |
Trendline options in Office (microsoft.com) Add a trend or moving average line to a chart (microsoft.com) |
Knowledge check
Complete the following five (5) tasks. Click the arrows to navigate between the tasks.
Statistics: an introduction
Statistics are the methods that allow you to work with data effectively. Specifically, business statistics provides you with a formal basis to:
- summarise and visualise business data
- reach conclusions about that data
- make reliable predictions about business activities
- improve business processes
- analyse and explore data that can uncover previously unknown or unforeseen relationships.41
It is vital that analysts understand conceptually what a statistical method does, so that they can correctly statistics and effectively carryout statistical analysis on datasets.
Basic terms
Statistics has its own vocabulary. Therefore, learning the precise meanings of basic terms provides the basis for understanding the statistical methods that we will discuss in this topic. 41
- Variable – defines a characteristic, or property of an item that can vary among the occurrences of those items.
- Descriptive statistics – defines methods that primarily help summarise and present data.
- Inferential statistics – defines a methods that use data collected from a small group to research conclusions about a larger group.
- A statistic – refers to a value that summarises the data of a particular variable.
- Population – consists of all items of interest in a dataset
- A sample – is a subset of a population.
The symbols used in the equations or formulas in this section can be defined as follows:
$$\textit{X}i=i^{th}\;\text{value of the variable} \;\textit{X}$$
$$\textit{N}=\text{number of values in the population}$$
$$\sum_{i=1}^NX_i = \text{summation of all} \;X_i\;\text{values in the population}$$
In this module, our focus is more on descriptive statistics. Therefore, let’s further explore the important numerical measures of descriptive statistics.
Read the summary of descriptive statistics and watch the embedded video at this Investopedia page that introduces important parameters.
Measures of location
Measures of location provides estimates of a single value that in some fashion represents the 'centring' of a set of data. 43(Evans 2021)
Measures of location are also commonly known as ‘measures of central tendency’.
Several statistical measures that characterise measures of location are as follows.
Arithmetic Mean
The average is formally called the arithmetic mean (or simply mean), which is the sum of the observations divided by the number of observations.
Mathematically, the mean of a population is denoted by the Greek letter µ. If a population consists of N observations, the population mean is calculated as follows.
$$\text{Arithmetic Mean}\;( \mu) = \frac{ \sum_{i=1}^NX_i}{N}$$
Median
The measure of location specifies the middle value when the data are arranged from least to greatest. Half the data are below the median and half the data are above it.
Mode
- This is an observation that occurs most frequently.
- This is most useful for datasets that contain a relatively small number of unique values.
- The mode does not provide much practical value for datasets with few repeating values.
Midrange
The midrange is the average of the largest and smallest values in the dataset.
Outliers
- Outliers are observations that are radically different from the rest.
- The mean is affected by outliers as it can pull the mean's value toward the extreme values.
- As opposed to the mean, the median is NOT affected by outliers.
Watch the following video to learn more about the measures of location.
Use Excel to analyse the following set of randomly generated numbers statistically. While this is not big data, the focus here is on analysis functions that can be applied to large data sets.
| 30 | 21 | 45 | 23 | 49 | 22 | 39 | 48 | 23 | 34 | 23 | 39 | 47 | 36 | 25 | 20 | 37 | 34 | 20 | 35 |
Copy this data into a column in Excel. (Hint: use Paste>special>Transpose)
Find the mean, median, mode and midrange for this data.
Check your answers.
| Measure | Result | Command line / equation |
|---|---|---|
| Mean | 32.5 | =AVERAGE(A1:A20) |
| Median | 34 | =MEDIAN(A1:A20) |
| Mode | 23 | =MODE(A1:A20) |
| Midrange | 34.5 | =AVERAGE(MAX(A1:A20),MIN(A1:A20)) |
Measures of dispersion
Dispersion refers to the degree of variation in the data that is the numerical spread (or compactness) of the data. 43(Evans 2021)
Measures of dispersion are also commonly known as ‘measures variation’.
Several statistical measures are used to characterise dispersion are as follows.
Range
This is the difference between the maximum value and the minimum values in the data set. The range can be computed easily by using the following formula.
$$\text{Range}=X_{Largest}-X_{Smallest}$$
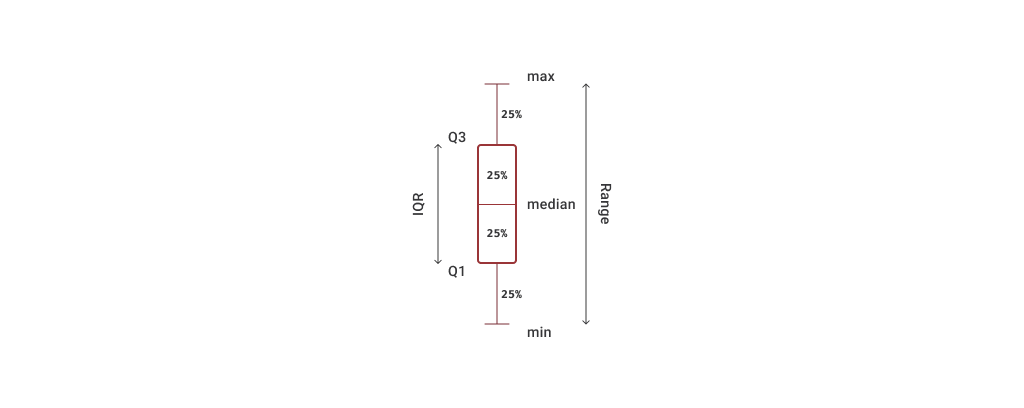
Interquartile range (IQR)
This is the difference between the first and third quartile. IQR is also known as the midspread. As the IQR only includes the middle 50% of the data, is not influenced by extreme values. This is sometimes used as an alternative measure of dispersion. The middle 50%, made up of the 25% of the distribution either side of the median can be seen in this diagram.
If a population consists of N observations,
- the first quartile (Q1) can be calculated as follows.
$$\text{First Quartile (Q}_1)= \frac{(N+1)}{4}$$
- the third quartile (Q3) can be calculated as follows.
$$\text{Third Quartile (Q}_3)= \frac{3(N+1)}{4}$$
- The interquartile range (IQR) can be calculated as follows.
$$\text{IQR}= \text{Q}_3-\text{Q}_1$$
This diagram shows how the spread of data can be grouped and described from the minimum to maximum values, grouped in quartiles that contain 25% of the data points. Note the IQR includes data points between the first and third quartiles (Q1 and Q3).
Variance
This is a more commonly used measure of dispersion, whose computation depends on all the data. The larger the variance, the more the data are spread out from the mean and the more variability one can expect in the observations.
The formula to calculate the variance of a population is as follows.
$$\sigma^2= \frac{ \sum_{i=1}^N (X_i- \mu)^2 }{N}$$
Standard deviation
This is the square root of the variance. Standard deviation is generally easier to interpret than the variance because its units of measure are the same as the units of the data. This is also a popular measure of risk, particularly in financial analysis because many people associate it with volatility in stock prices.
The formula to calculate the standard deviation of a population is as follows.
$$\sigma= \sqrt{\frac{ \sum_{i=1}^N (X_i- \mu)^2 }{N}}$$
Coefficient of variation
This provides a relative measure of the dispersion in data relative to the mean and is defined as follows.
$$\text{CV}= \frac{Standard \;deviation}{Mean}$$
Standardised values (Z-score)
Another important measure that analysts need to be familiar is ‘Z-score’.
The Z-score is a standardised value that provides a relative measure of the distance an observation is from the mean, which is independent of the unit of measurement.
$$\text{Z-score}= \frac{(X_1-\mu)}{ \sigma}$$
Watch the following video learn more about measure of dispersion (variation).
Use Excel and the data from the previous exercise.
Q1. Find the standard deviation and the variance. (Hint: instead of individual steps, use the Analysis>Data Analysis function and select descriptive statistics)
Q2. Plot a box and whisker chart. (Hint: instructions)
Q1. Check your answers.
| Mean | 32.5 |
| Standard Error | 2.233123845 |
| Median | 34 |
| Mode | 23 |
| Standard Deviation | 9.986833437 |
| Sample Variance | 99.73684211 |
| Kurtosis | -1.28251208 |
| Skewness | 0.2541605 |
| Range | 29 |
| Minimum | 20 |
| Maximum | 49 |
| Sum | 650 |
| Count | 20 |
Q2.

Measures of shape
Calculating and examining the average and standard deviation helps describe the data, but the shape of the distribution of the data can yield further insights.
Normal distribution
A distribution curve has the size of each data point on the horizontal axis and the frequency at which it occurs on the vertical axis. Most data tend to show a normal distribution, sometimes called a bell curve, due to its shape. For example, the heights of a group of people will tend towards a normal distribution, with most people close to average height, but with some shorter people and some taller.

For a normal distribution, the mean, median and mode would have the same centred value as shown in the diagram.

With an understanding of the shape of the normal distribution, we can see how the standard deviation is such a useful measure. Recall that the symbol μ represents the mean and σ the standard deviation.
Confidence level
Consider the following diagram that shows the central mean (μ). If we include all the data one standard deviation (σ) either side of the mean, we include 68% of the data or close to two thirds. Similarly, two standard deviations either side of the mean includes 95% of the data. Three standard deviations either side is referred to as “almost all” the data, or 99.7% confidence.
As you may start to appreciate, the smaller the standard deviation, the narrower the distribution.

This video summarises normal distributions and standard deviation and introduces the next topic of skewness.
Skewness
Sometimes data distribution is not normal and is pulled to the right by many larger data points (positive skew), or to the left by many smaller data points (negative skew). The skewness affects the mean and median by moving them in the direction of the skew. The equation for skewness is:
$$\frac{3(\text{Mean-Median)}}{\sigma}$$
Examples of right and left skewed distributions and the effect on the averages is shown in the following diagrams.

Watch the following video learn more about skewness.
Kurtosis
Kurtosis is a measure of the outliers in a data set. A normal distribution has a kurtosis of 3. If the kurtosis is greater than 3, the shape of the distribution is taller and thinner than a normal distribution, but the tails are longer as the outliers are further from the mean. If the kurtosis is less than 3, then more outliers are closer to the mean. As an example, a uniform distribution would be an extreme case of negative kurtosis.

Note: a distribution with kurtosis not equal to 3, or any skewness, is not a normal distribution.
Measures of association
Understanding the relationship between two variables is important to make good business decisions. Therefore, it is helpful to understand the statistical tools for measuring these relationships. 43
Covariance
A measure of the linear association between two variables, X and Y. However, the numerical value of the covariance is difficult to interpret because it depends on the units of measurements of the variables.
Correlation
A measure of the linear relationship between two variables, X and Y which does not depend on the units of measurements. Correlation is measured by correlation coefficient.
The possible values for the correlation coefficient when calculated would range between -1 and 1.
Knowledge check
Complete the following three (3) tasks. Click the arrows to navigate between the tasks.
There are many programming languages used for big data testing and analysis, such as Python and R. However, for the purpose of this module, you will be introduced mainly to Power Query M Formula Language (informally known as ‘M code’ or ‘M language’) and DAX (Data Analysis Expressions) as you will be working with these languages to perform big data analysis tasks using Microsoft Power BI platform from Topic 4 onwards.
To perform searches of combined big data you will need to understand and learn the basic industry protocols and procedures to write queries and scripts using M code and DAX. So, let’s begin.
Power Query M Formula Language (M code)
The M language is the data transformation language of Power Query. It is mainly used to clean, filter out data, change column formatting and so on.
The Query Editor in Power BI provides a powerful graphical interface that allows you to perform complex data modifications without having to look into the M code that the Query Editor is building behind the scenes.
Refer to the article Power Query M language specification – Power Query M | Microsoft Learn to learn more details about the basic rules for using the Power Query M formula language.
Rules for searching and combining data using queries
The following types of queries can be used to search for and combine data in Power Query.
- Append queries –This is a type of operation that creates a single table by adding the contents of one or more tables to another and gathers the column headers from the tables to create the schema for the new table. To learn more, refer to the article Append queries - Power Query | Microsoft Learn
- Merge queries – This is a type of operation that joins two existing tables together based on matching values from one or multiple columns. Analysts can choose to use different types of joins, depending on the output required. To learn more about the join types used when merging queries refer to the article Merge queries overview - Power Query | Microsoft Learn.
Knowledge check
Refer to the recommended resources and complete the following two (2) tasks. Click the arrows to navigate between the tasks.
- Append queries - Power Query | Microsoft Learn
- Merge queries overview - Power Query | Microsoft Learn.
DAX rules and requirements
DAX formulas are similar to those used in Excel tables. However there some key differences.
DAX formulas are often written as calculations and comes in three forms.44
- Calculated measures – used to perform aggregations (e.g. calculate totals, count distinct values etc.)
- Calculated columns – used to add additional columns to tables in a dataset
- Calculated tables – used to create a new table with required columns.
Let’s understand the basic rules that you need to follow when writing DAX formulas and specific object naming requirements. We need to consider the structure or format for a DAX formula, then review some commonly used function and how to build statements. Finally, these can be assembled to create a query to help make sense of big data and build your analysis.
Basic rules
When writing DAX formulas for calculated columns or measures it is important to follow these general rules or protocols.
- A DAX formula always starts with an equal (
=) sign - After the equals sign, comes the expression which may include elements such as statements, functions, operators, values etc. It is important to note that expressions:
- are always read from left to right
- use parentheses to control the order in which the elements are grouped
- A DAX function always references a complete column, measure or table. This is commonly known as the fully qualified name of that object. For example:
- The fully qualified name of a column refers to the table name, followed by the column name in square brackets. For example,
'AUS Order'[Products]. - The fully qualified name of a measure refers to the table name, followed by the measure name in square brackets. For example,
'AUS Order'[Profit].
- The fully qualified name of a column refers to the table name, followed by the column name in square brackets. For example,
Object naming requirements
- All object names are case-insensitive. (e.g. The table names
'SALES'and'Sales'would represent the same table name).- Note that the term object here refers to tables, columns, measures etc
- The names of objects must be unique within their current context. For example:
- measure names must be unique within a model
- column names must be unique within a table
- table names must be unique within a database
- Leading or trailing spaces that are enclosed by name delimiters, brackets or single apostrophes are valid in the names of tables, columns, and measures.
- If the name of a table contains any of the following, you must enclose the table name in single quotation marks.
- Spaces (e.g.
'Order Detail') - Reserved keywords (e.g.
'Analysis Services'cannot be used as a table name unless it is enclosed in quotation marks) - Disallowed characters
.,;':/\*|?&%$!+=()[]{}<> - Characters outside the ANSI alphanumeric character range
- Spaces (e.g.
Take a look at the following examples of object names used within DAX formulas.
| Example | Object type | Comments on the naming requirement |
|---|---|---|
Customer |
Table name | This table name does not contain any spaces or other special characters. Therefore, the name does not need to be enclosed in quotation marks. |
'AUS Orders' |
Table name | This table name contains a space therefore it needs to be enclosed in single quotation marks. |
'Discount%' |
Table name | This table name contains a special character. Therefore it needs to be enclosed in single quotation marks. |
Orders[Cost] |
Fully qualified column name | The table name precedes the column name and the column name is enclosed in square brackets. |
Orders[Profit] |
Fully qualified measure name | The table name precedes the measure name and the measure name is enclosed in square brackets. |
[Cost] |
Unqualified column name |
This is just the column name in square brackets. This can be used in certain situations in formulas such as:
|
'AUS Order'[Cost] |
Fully qualified column in table with spaces | The table name contains spaces, so it must be enclosed in single quotation marks. |
Operators
There are different types of operators used when writing DAX formulas. Some of the frequently used DAX operators are listed in the following table.45
| Operator type | Metacharacter symbols | Meaning |
|---|---|---|
| Arithmetic operators | + |
Addition |
- |
Subtraction | |
/ |
Division | |
* |
Multiplication | |
| Comparison operators | = |
Equal to |
== |
Strict equal to | |
> |
Greater than | |
< |
Less than | |
<= |
Less than or equal to | |
>= |
Greater than or equal to | |
<> |
Not equal to | |
| Text concatenation operator | & |
Connects two values to produce one continuous text value |
| Logical operators | && |
AND condition |
|| |
OR condition | |
| Parenthesis operator | () |
Used for precedence order and grouping of arguments |
For more information on DAX operators, refer to the DAX operators - DAX | Microsoft Docs.
Now that you are aware of the general rules for writing DAX formulas, let’s look into the structure and basic syntax of a DAX formula.
DAX formula syntax
Before you can write your own DAX functions you need to be familiar with the various elements that make up a DAX formula. 46
Following are the basic elements that make up a DAX measure.
Simply, what this DAX statement does, is to create a measure named Total Costs that calculates (=) the SUM() of values in the CostAmount column in the Orders table.
Let’s understand each of the elements in this DAX measure.
- The name of the new measure (e.g.
Total Costs) - The beginning of the formula is indicated by an equals sign operator (
=) - DAX function (e.g.
SUM()– used to add all values in a given table’s column (e.g.Orders[CostAmount])) - Parenthesis
(), which surrounds an expression that contains one or more arguments. Most functions require at least one argument. An argument passes a value to a function. - The name of the table that the formula applies to (e.g.
Orders) - The name of the column that the formula applies to (e.g.
CostAmount) - Calculated measure name
- DAX formula
Let us take a look at some examples of how the DAX formula syntax can be used to create a calculated column, measure and table. In each of these examples notice how the syntax rules are followed.
- DAX column/measure name (e.g.
Profit,Total Profit,Customer) - DAX Formula
DAX Functions
DAX functions help to perform commonly used data calculations on data models, databases, tables etc.
There are a variety of DAX functions that are inbuilt in the DAX language that can be used for various purposes when writing DAX formulas. It is important to note that each DAX function, has specific syntax rules that must be followed to ensure the script executes without any errors.
For more information on DAX functions and their specific syntax rules, refer to the DAX function reference - DAX | Microsoft Docs.
The following table explores and provides examples of some of the DAX functions, their purpose and how they can be used when writing queries.
| Function type | DAX functions | What it does | Example |
|---|---|---|---|
| Aggregation functions |
SUM()
|
Used to add all the numbers that are in a column. |
The following example adds all the numbers in the =SUM(Sales[Cost]) |
COUNT()
|
Counts the number of rows in the specified column that contain non-blank values. |
The following example returns a whole number after counting the values in the =COUNT(Product[Product ID]) |
|
DISTINCTCOUNT()
|
Used to return the number of distinct values in a given column. |
The following example returns the calculated number of distinct values from the =DISTINCTCOUNT(Category) |
|
AVERAGE()
|
Returns the average (arithmetic mean) of all the numbers in a column. |
The following example returns the average of the =AVERAGE(Sales[Revenue]) |
|
MAXA()
|
Returns the largest value in a column. |
The following example returns the largest value of the =MAXA(Sales[Revenue]) |
|
MINA()
|
Returns the smallest value in a column. |
The following example returns the minimum value of the =MINA(Sales[Revenue]) |
|
| Math and trig functions |
DIVIDE()
|
Used to perform divisions and returns alternate result or BLANK() on division by 0. Refer to: DIVIDE function vs divide operator (/) in DAX - DAX | Microsoft Learn to understand why this function is used instead of ‘/’ to perform divisions. |
The following example returns 5.
=DIVIDE(10,2)
The following example returns a blank.
=DIVIDE(10,0)
The following example returns 1.
=DIVIDE(10,0,1)
|
| Statistical functions |
MEDIAN()
|
Returns the median of numbers in a column. |
The following example returns the median value of the =MEDIAN(Sales[Revenue]) |
STDEV.P()
|
Returns the standard deviation of the entire population. |
The following example returns the standard deviation value of the =STDEV.P(Sales[Revenue]) |
|
PERCENTILE.INC()
|
Returns the kth percentile of values in a range, where k is in the range 0-1 inclusive. |
The following example returns the first percentile value of the =PERCENTILE.INC(Sales[Revenue,0.25]) The following example returns the third percentile value of the =PERCENTILE.INC(Sales[Revenue,0.75]) Refer to PERCENTILE.INC function (DAX) - DAX | Microsoft Learn for more details. |
|
NORM.DIST()
|
Returns the normal distribution for the specified mean and standard deviation. |
Returns the normal distribution, for the X (32) value, having a mean of 30 and standard deviation of 1.5, for a cumulative distribution.
=NORM.DIST(32,30,1.5,TRUE)
Refer to NORM.DIST function (DAX) - DAX | Microsoft Learn for more details. |
Putting it all together
Watch the following video from Microsoft Power BI which demonstrates how the statements, functions, values, operators etc. you’ve learnt in this topic work together in DAX queries and the output it generates in Power BI Desktop.
Note: You will learn to use Power BI Desktop later on in the next topic. Therefore, your focus at this point should be on learning the syntax and the basic rules for using DAX scripts.
In the following series of examples and activities, you will see how statements, functions, values, operators etc. all work together in DAX queries.
For each question within the following activities, make an attempt to write DAX queries yourself before looking at the solutions and answers provided.
Consider the following Orders table.
| Order ID | Product ID | Product Name | Sales | Cost | Quantity |
|---|---|---|---|---|---|
| 001 | 101002 | Colored Pencils | $ 3.50 | $ 1.00 | 5 |
| 001 | 101004 | Flourescent Highlighters | $ 5.00 | $ 2.50 | 2 |
| 002 | 101001 | Crayons | $ 7.50 | $ 3.00 | 1 |
| 002 | 101003 | Dustless Chalk Sticks | $ 2.50 | $ 1.50 | 2 |
| 002 | 101004 | Flourescent Highlighters | $ 5.00 | $ 2.50 | 1 |
| 003 | 101003 | Dustless Chalk Sticks | $ 2.50 | $ 1.50 | 10 |
| 003 | 101004 | Flourescent Highlighters | $ 5.00 | $ 2.50 | 10 |
Complete the following questions:
- Create a measure called '
Total Sales'that calculates the total sales value for the quantity of products sold. - Create a measure called '
Total Cost'that calculates the total cost for the quantity of products sold. - Create a measure called '
Gross Profit'that calculates the difference between the previously created measures,Total SalesandTotal Cost. - Create a measure called '
Profit Margin'that calculates the division of theGross Profitvalue byTotal Salesvalue and ensures that a values of ‘0’ is indicated if the returned value equals ‘0’. - Create a measure called
Distinct productsthat counts the number of different items in the 'Product ID'column.
-
Total Sales = Orders[Sales]*Orders[Quantity]
-
Total Cost = Orders[Cost]*Orders[Quantity]
-
Gross Profit = [Total Sales]-[Total Cost]
-
Profit Margin = DIVIDE([Gross Profit],[Total Sales])
-
Distinct products = DISTINCTCOUNT(Orders[Product ID])
Additional resources
Refer to the following sources to learn more about DAX syntax and how it can be used.
- DAX Guide
- Data Analysis Expressions (DAX) Reference - DAX | Microsoft Docs
- DAX Resource Center - TechNet Articles - United States (English) - TechNet Wiki (microsoft.com)
Adding comments in DAX scripts
Adding comments will not affect the performance of the scripts/queries but would make it easier for others to understand the written code and make changes later on if needed.
These examples show the different methods of commenting
Method 1: Start your comment with two hyphens/dashes (--).
Example: The comment is embedded in-line using the hyphens indicating that anything after the hyphens is the comment text.
Orders = SELECTCOLUMNS('Company Data', --this is an inline comment "Customer ID", [Customer ID], "Customer Name", [Customer Name], "Customer Address", [Customer Address]
Method 2: Begin the comment with the // symbol.
Example: The // symbol indicates that the entire line contains comment text.
Orders = SELECTCOLUMNS('Company Data', "Customer ID", [Customer ID], // this is a single-line comment "Customer Name", [Customer Name], "Customer Address", [Customer Address]
Method 3: Commenting-out multiple lines of code
Place the code in between /* and */ symbols.
Example: The specific two lines of the script won’t execute because it is commented out.
Orders = SELECTCOLUMNS('Company Data', "Customer ID", [Customer ID], /* this is a multi-line comment "Customer Name", [Customer Name], "Customer Address", [Customer Address] */
The final activity for this topic is a set of questions that will help you prepare for your formal assessment.
Knowledge check
Complete the following two (2) tasks. Click the arrows to navigate between the tasks.
An organisation must have clear policies and procedures to run smoothly and efficiently. Procedures and policies must align, but they are not the same thing.
- Policies are guidelines that outline an organisation’s rules and requirements. For example, a policy could state requirements for workplace safety or employee conduct.
- Procedures are steps or specific actions required to carry out the policy. For example, the workplace procedure may state how to perform a safety audit or employee conduct expectations.
Organisations will have policies and procedures coving all aspects of the business, including guidelines and requirements for handling and analysing big data and how the results are stored and disseminated. You must work within your organisation’s policies and procedures at all times and those relevant to big data testing.
Policies and procedures apply to the entire process of big data analysis.

For this unit you must particularly be familiar with the following policies and procedures.
Identifying big data sources
Data source identification policies and procedures
These policies and procedures provide guidelines on how to recognise where a dataset is sourced from. It also helps analysts understand how to use the dataset appropriately whilst complying with any legislative requirements that may apply.
Data may be sourced internally (in house) or externally to an organisation.
Establishing and confirming categories to be applied in analysis
Data categorisation procedure
These procedures explain how to analyse big data in different categories, including text, audio-video, web and network format.
There may be different approaches or strategies followed when categorising the data, which may vary from organisation to organisation. Data categorisation procedures may include templates with specific guidelines that would help analysist to categorise data in a specific way.
These procedures include instructions on:
- how data categories can be established, considering the requirements of the data analysis project
- how the established categories can then be confirmed before it is applied in the analysis.
Analysing data to identify business insights
Data analysis procedure
These procedures provide guidelines on how to evaluate and investigate the big dataset to find trends, and forecasts to identify business insights. These procedures include instructions on:
- specific methodologies to use during the analysis
- visualisation guidelines and specifications
- how statistical analysis can be conducted to verify initial analysis results
- sample formulas and scripts that can be used when conducting the analysis
- how analysis reports should be developed.
Integrating big data sources including structured, semi-structured, and unstructured
Procedure for integrating big data sources
These procedures provide guidelines on how to combine datasets from different sources that may have different formats and data structures such as structured, semi-structured and unstructured.
Different approaches or strategies must be used when handling different formats of data.
Combining external big data sources, such as social media, with in-house big data
Procedure for combining external big data sources
Provides guidelines on how to combine big data sources such as social media, with in-house big data.
As external big data sources may include data in different formats (mostly unstructured or semi-structured), these must be transformed into structured form before combining with in-house data.
Reporting on analysis of big data, including the use of suitable reporting and business intelligence (BI) tools
Policies and procedures for reporting on big data analysis
Provides best practices and guidelines to ensure that the analysis of the big dataset is communicated using the appropriate business intelligence and reporting tools.
These procedures include instructions on:
- how to present analysis results clearly and consistently using standard representations (e.g charts, graphs etc)
- specific report structures that should be used (formats, style guides etc)
- which business intelligence tool to use, and specific guidelines on how to use certain reporting features of the tool
- how to store the analysis results and associated supporting evidence considering any legislative requirements.
Knowledge check
Complete the following four (4) tasks. Click the arrows to navigate between the tasks.
Topic summary
Congratulations on completing your learning for this topic Fundamentals of analysing big data.
In this topic you have learnt the following fundamental concepts behind analysing big data.
- Legislative requirements relating to analysing big data, including data protection and privacy laws and regulations.
- Basic concepts of big data including the relationship between raw data and datasets and sources of uncertainty within big data.
- Common models and tools to analyse big data, including features and functions of Excel software for advanced analytics.
- Analytical techniques used to analyse transactional and non-transactional data.
- Classification categories of analytics, including text, audio/video, web and network.
- Industry protocols and procedures required to write basic queries to search combined big data.
- Organisational policies and procedures relating to analysing big data.
Check your learning
The final activity for this topic is a set of questions that will help you prepare for your formal assessment.
End of chapter quiz:
Knowledge check
Complete the following seven (7) tasks. Click the arrows to navigate between the tasks.
Assessments
Now that you have completed the basic knowledge required for this module, you are ready to complete the following assessment event:
- Assessment 1 (Online Quiz)
What’s next?
Next, we will dive into how data analysis projects are initiated in organisations by understanding how to determine the purpose and scope of big data analysis projects.
